










Note:
AI models and their capabilities are advancing rapidly. The information in this article is accurate as of May 30, 2025. When you read this, newer models may have been released, and some details might change.
The portfolio reWireAdaptive, in association with the @reWirebyAutomation channel, presents an article on LLM suitability for automation needs. This article, titled "Simplified Suitability Analysis," explores how best-fit LLMs are selected in AI coding assistants to enhance automation practice and equip individuals for enterprise readiness.
This article focuses on the use of GitHub Copilot with different AI models for coding in IDEs such as VSCode and JetBrains IntelliJ IDEA.
As we observe advancements in LLMs from leading vendors, AI’s influence is increasingly significant in the development space, particularly in coding activities. This is further supported by IDE integrations with coding AI assistants like GitHub Copilot, which provides users access to various LLM models from OpenAI, Anthropic, and Google.
Given these AI advancements and their integration in coding, the same applicability extends to test automation, especially for those using open-source technologies and maintaining a coding-based approach (e.g., Selenium WebDriver automation, Rest Assured for API automation, Selenium with other languages like Python, JavaScript, and Playwright automation). This information will be helpful for those who mainly depend on code-centric automation and automation practice.
For users who build scripts using GUI tools or low-code/no-code in-house platforms and are considering AI-enabled models, this information might still be useful for your automation practice.
Note: This is not applicable to commercial tools, as vendors typically select leading vendors' LLMs and customize as per the enterprise platform.
I have considered open-source technologies automation under two categories: Enterprise and Personal.




Enterprise:
This falls under organizational AI governance. You must follow approved AI tools for IT development operations. If your organization has approved GitHub Copilot or any other coding assistant with a specific model, adhere to those models and protocols. As an advisory, if your organization seeks guidance on automation suitability models, you can reference the “Personal” study below, which is focused on individual practice and insights.
Personal:
This covers individuals’ exploration and learning journey using open-source technologies, exploring new features, developing utilities, and coding-based automation. So, work is often done in IDEs like VSCode or JetBrains family IDEs based on learning intent.
To provide clear, straightforward insights, I am considering VSCode with GitHub Copilot AI Assistant for Playwright automation, and JetBrains IntelliJ IDEA with GitHub Copilot AI Assistant for Selenium with Java automation.
Recently, Microsoft announced GitHub Copilot integration into VSCode and other major IDEs (see my previous article for more). GitHub Copilot allows users to select from multiple LLMs from vendors such as OpenAI, Anthropic, and Google.
Choosing the right model can be confusing for users, and it’s easy to lose sight of the original intent. Below are quick insights, based on information from GitHub and LLM vendors, to help clarify model selection for coding automation tasks.
In any automation project, the codebase typically includes global configurations, generic and application-specific library components, test data, and test scripts. Key activities involve library development, script development, code fixes, end-to-end execution, Docs generation, and suite readiness.
With this context, I have listed technical factors (related to core capabilities), generic factors specific to test automation, and business factors to help determine which LLMs are best suited for your needs.
Technical factors:
· Content awareness at scale
· Generating code to intent
· Generating libraries to intent
· Reasoning
· Agent capability
Common/generic factors for test automation:
· Intent understanding and generating code
· Code explanation
· Comments/documentation generation
· Code fixes
Business factors:
· Performance, scalability, and cost
Model Suitability:
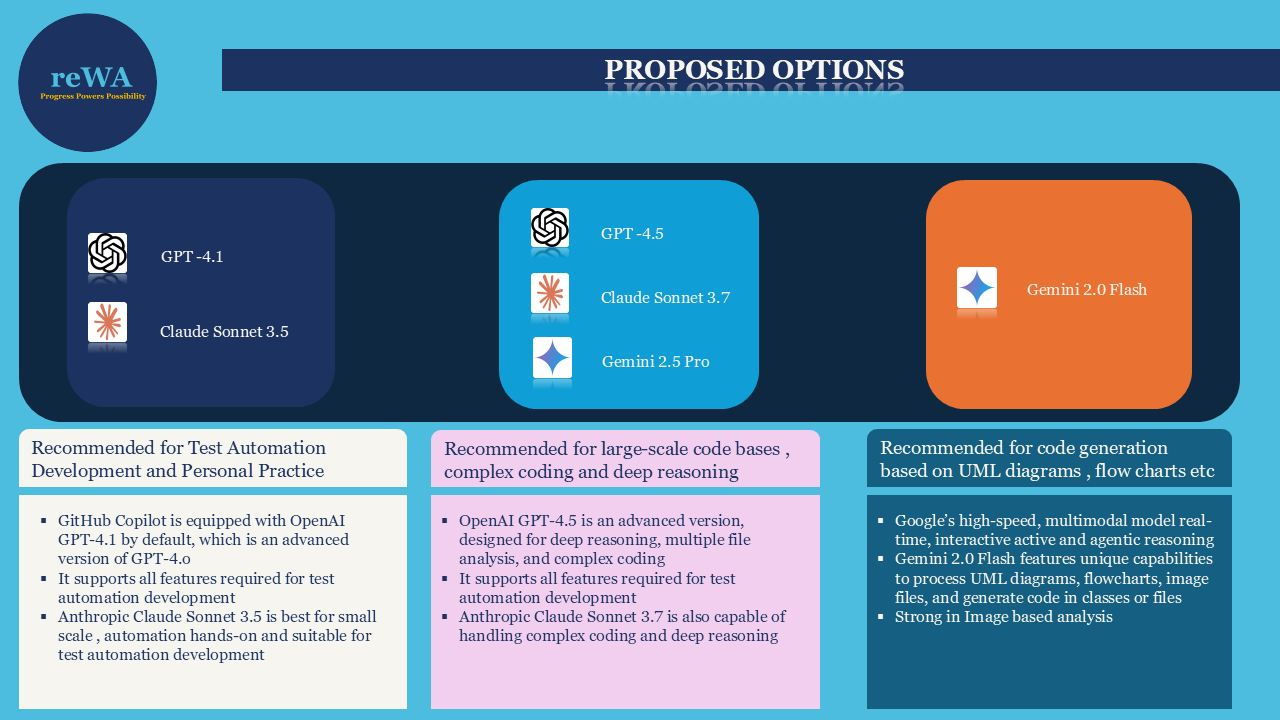
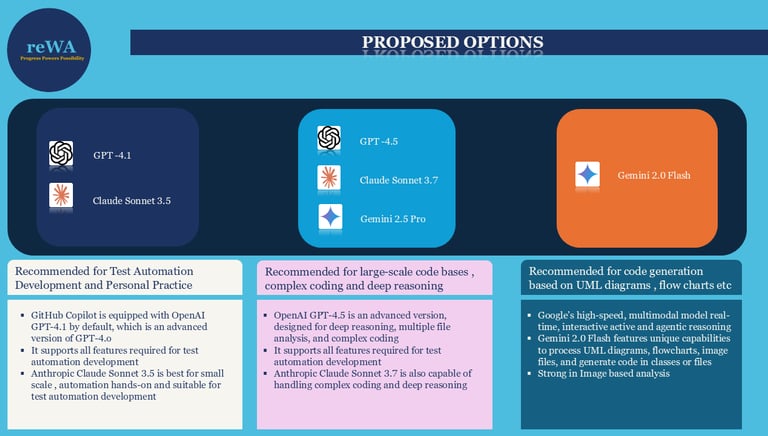
Based on technical factors, GPT-4.1 and GPT-4o are the best fit for default automation support in both personal practice and enterprise use (though cost should be considered) when using GitHub Copilot.
Anthropic’s Claude Sonnet 3.5 model is also a strong fit for personal experience and is sufficient for most practice needs. Notably, enterprise customers often prefer it for a wide range of coding requirements.
Claude Sonnet 3.7 is more suited for large-scale algorithmic tasks, which are generally beyond the needs of typical test automation.
Google’s Gemini models, such as 2.5 Pro and 2.0 Flash, are optimized for large-scale requirements (for example, generating code from models or diagrams using 2.0 Flash), which may not be necessary for personal test automation or utility development.
Overall, OpenAI’s GPT-4.1 (the default for GitHub Copilot) and Anthropic Claude Sonnet 3.5 are best suited for both Test Automation development with an optimized codebase and personal automation practice, especially for hands-on work in VS Code and IntelliJ IDEA.
This analysis is based on current automation requirements across GUI, API, database, and security automation. GPT-4.1 and Claude Sonnet 3.5 have proven feasible and suitable according to the technical and generic factors discussed above and have shown good results in my experience. These are predominantly needed for automation practice and hands-on work.
Additionally, the key is to stay relevant by gaining hands-on experience with the optimal required models, such as GPT4.1 or Claude Sonnect 3.5, rather than always chasing the latest updates. Building a strong foundation in model selection and practical use makes it easier to adapt as new advancements emerge.
Final Insights: It is good practice to understand and focus on one optimized model that is readily available and meets your automation practice needs. This approach also becomes valuable for enterprise work when individuals gain real-world experience. The models shortlisted above are well-suited for building the knowledge needed to become an AI-powered automation practitioner and will support continuous growth throughout your journey, delivering both personal and business results. Gaining this experience is especially helpful as LLM advancements continue to progress rapidly and iteratively.
| Refer to the infographic embedded for Final Insights:



Please refer to the voiceover for the “LLM – Simplified Suitability Analysis for Automation” session available on the @rewirebyautomation YouTube channel.




Stay tuned for the next article and session from rewireAdaptive
This is @reWireByAutomation, (Kiran Edupuganti) Signing Off!
With this, @reWireByAutomation has explained a “AI Coding Assistants & Test Automation: A Simplified Suitability Analysis” from an AI-powered automation objective perspective.
Connect
© 2026. All rights reserved.
Personal:
Discussions: